2025-07-28万象ai
GMICloud推出“AI应用构建成本计算器”,精准破解AI应用海外市场落地难题
当全球AI应用开发者将目光投向海外市场时,“商业化成本高”“回本周期长”已成为横亘在规模化落地前的核心挑战。WAIC2025期间,GMICloud正式发布自研“AI应用构建成本计算器”(体验网址:http://agent-calculator.gmi-inference-engine-analytics.com/),通过实时量化不同场景下的算力成本、时间损耗与供应商性价比,为开发者提供成本规划支持。
根据artificialanalysis.ai的数据及GMIcloud对典型场景(如code-building)的评估,使用GMICloud方案可使海外IT成本降低40%以上,回本周期缩短至行业平均水平的1/3。
海外AI应用商业化的经济与时间成本:Token消耗是深水区,从技术研发到市场验证要经历漫长征途Token作为AI文本处理的基本单位,其消耗成本直接决定商业可行性。在全球AI应用出海浪潮中,动态Token消耗成本黑洞与从零研发的时间损耗正成为企业核心痛点。据行业数据显示,GPT-4Turbo处理单次多步骤Agent任务消耗可达200万Token(成本约2美元),而工程化部署周期普遍被低估60%。
传统模式下,Token成本犹如无底洞。以生成千字文案为例,GPT-4Turbo需消耗0.12美元,而其他语言可能会因分词复杂性,同等文本较英文多消耗20%-50%Token。像滑动窗口机制,处理10KToken文档时实际消耗激增40%,人工测算几乎无法捕捉。
同时,Token吞吐速度正成为决定AI应用、AIAgent构建的“隐形计时器”,构建者普遍因低估token处理效率对研发周期的影响,导致大量AI应用错过最佳市场窗口期。某头部电商企业在开发智能客服AI时,原计划以开源模型为基础,6个月内完成应用上线。然而实际研发中,由于对话数据量庞大,模型每秒处理Token数量远低于预期,训练单个优化版本就需耗时数周。特别是在多轮迭代中,因Token处理效率不足,数据清洗、模型微调与部署等环节频繁出现延迟,最终项目耗时18个月才交付,比原计划延长两倍,错过了很多市场商业化机会。
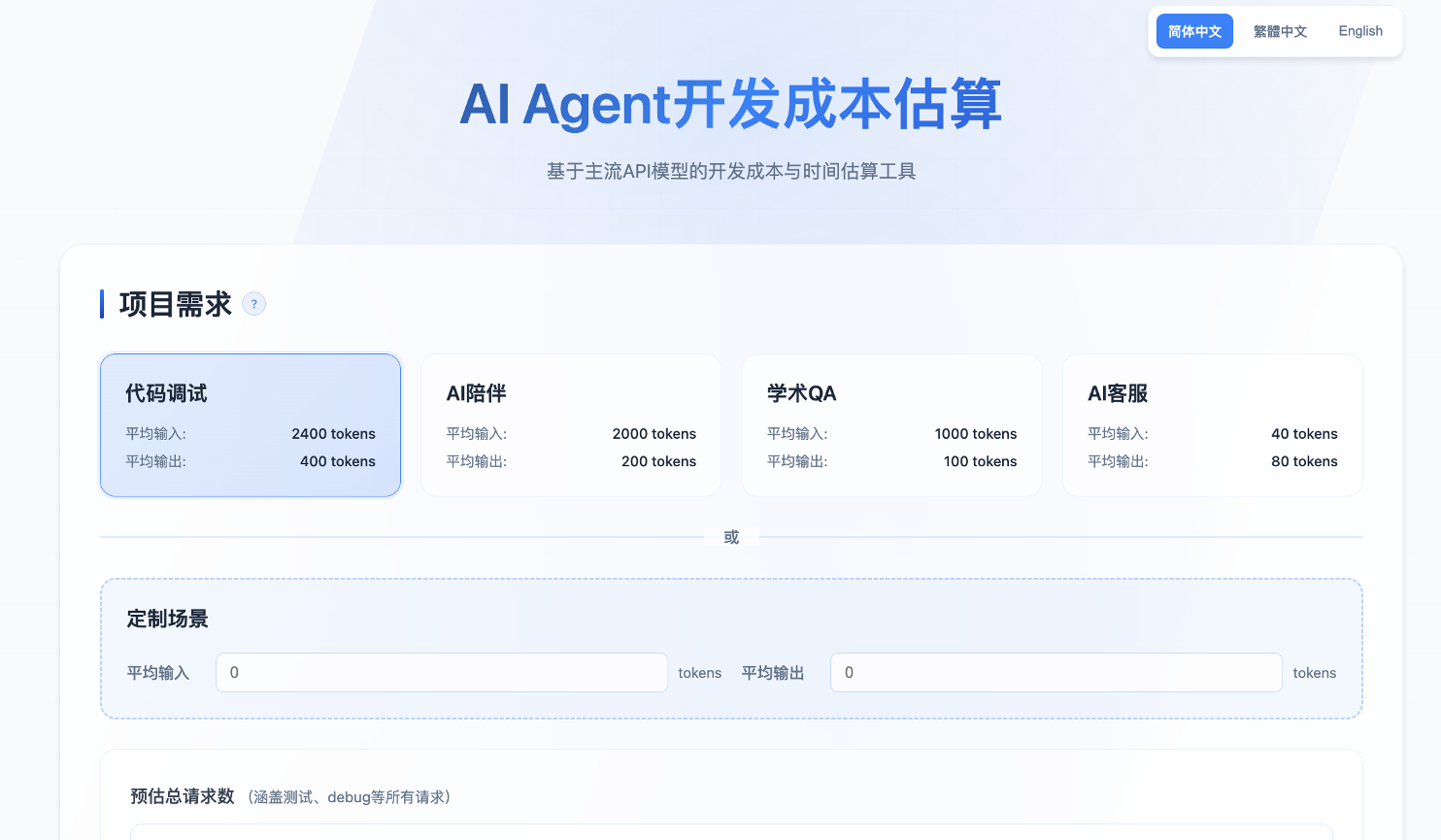
而GMICloud“AI应用构建成本计算器”的创新便在于双轨核算机制,基于Token数量与单价(区分输入/输出),核算AI应用/AIAgent构建总花费;结合Token吞吐量(输入/输出速度),计算处理总请求的耗时。同时,该工具还能实时对比OpenAI、Anthropic等15家供应商的Token单价,自动标记InferenceEngine等低成本替代方案。
“我们发现,部分大模型推理API服务虽单价低,但吞吐量不足导致服务时长激增,反而推高AI应用构建的隐性成本。”GMICloud技术VPYujingQian指出,“计算器帮助客户穿透‘低价陷阱’,真正实现TCO(总拥有成本)优化。”
从成本计算器到商业化加速器:GMICloudInferenceEngine很多人以为便宜就意味着速度慢,其实不然。就实践数据来讲,GMICloudInferenceEngine处理数据的速度达到每秒吞吐量161tps,处理900万字的输出任务仅需15个多小时。而有些服务商虽然低价,但每秒只能处理30个字,同样的任务需要83个小时(相当于3天半)才能完成,严重影响业务效率。举一个例子,假设你要开发一个代码辅助开发工具,每月处理1万次请求,每次输入3000字、输出900字。用GMICloud总共花费30.3美元,15个半小时就能完成任务;而用某知名云服务则要花75美元(约520元),且需要40多个小时才能完成。
而这一切都是得益于GMICloudInferenceEngine的底层调用GMICloud全栈能力,其底层调用英伟达H200、B200芯片,从硬件到软件进行了端到端的优化,极致优化单位时间内的Token吞吐量,确保其具备最佳的推理性能以及最低的成本,最大限度地帮助客户提升大规模工作时的负载速度以及带宽。同时,其让企业以及用户进行快速部署,选择好模型后即刻扩展,几分钟之后就可以启动模型,并直接用这个模型进行Serving。
三、快速开始体验GMICloud“AI应用构建成本计算器”
GMICloud“AI应用构建成本计算器”工具具有极强的易用性。用户只需简单选择「Agent场景」与「预估总请求量」,即可快速获得AI应用构建所需的「耗时」与「成本」。此外,还可自由设置平均输入、输出等多种参数,既简单易用,又灵活精准。
欲了解更多详情或工具试用,可访问GMICloud官网:https://www.gmicloud.ai/
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表本站立场。文章及其配图仅供学习分享之
新品榜/热门榜